Apache Zookeeper
Uno de los componentes más importantes en nuestros clúster surge con Apache Zookeeper, este componente nace con HBase, una base de datos NoSQL de la Fundación Apache.
Zookeeper se agrega a el sistema Hadoop2, gracias a este componente podemos tener una gran cualidad en nuestro clúster como lo es la alta disponibilidad, pero, ¿Cómo es que se logra algo como esto?, Primero debemos entender cuál es la finalidad de este componente.
Apache Zookeeper fue diseñado como una herramienta de coordinación para sistemas distribuidos, una de las principales características que lo hacen muy eficaz en su desempeño, es que la información que le pertenece a Apache Zookeeper esta cargada en memoria, pero uno se preguntará, que tiene de eficiente poner la memoria de un coordinador de sistemas distribuidos en memoria, el punto de esto esta en la magia para lo que esta herramienta fue diseñada, y como su definición lo dice, fue para la coordinación, como coordinador no necesitas conocer toda la información contenida en un sistema distribuido, ya que solo le bastaría con conocer lo más relevante.
Ejemplo: El caso más común es el clúster de hadoop, lo podemos ver como un sistema distribuido, entonces, ¿Qué debería saber el zookeeper acerca de hadoop?, debería tener la información de que nodo es el namenode, la información acerca de los namenode que se encuentran en standby, Apache recomienda tener un máximo de 5 namenodes en un clúster y como mínimo para la alta disponibilidad un número de 2. Así que la información es mínima que en realidad guardamos en un clúster llamado como ensamblado cuando nos referimos a Zookeeper.




Como anteriormente definimos un ensamblado debe ser de la forma anterior de acuerdo al teorema CAP, entonces tenemos un ensamblado de 2n+1 servidores, entonces dijimos que el quorum es el número de votos necesarios mínimos para finalizar una operación, entonces esto nos hace pensar que debería ser el número de servidores en el ensamblado más uno entre 2.

Entonces el quorum esta formado en cualquier ensamblado por un número de n+1, para sentenciar una operación como finalizada.
Zookeeper se agrega a el sistema Hadoop2, gracias a este componente podemos tener una gran cualidad en nuestro clúster como lo es la alta disponibilidad, pero, ¿Cómo es que se logra algo como esto?, Primero debemos entender cuál es la finalidad de este componente.
Apache Zookeeper fue diseñado como una herramienta de coordinación para sistemas distribuidos, una de las principales características que lo hacen muy eficaz en su desempeño, es que la información que le pertenece a Apache Zookeeper esta cargada en memoria, pero uno se preguntará, que tiene de eficiente poner la memoria de un coordinador de sistemas distribuidos en memoria, el punto de esto esta en la magia para lo que esta herramienta fue diseñada, y como su definición lo dice, fue para la coordinación, como coordinador no necesitas conocer toda la información contenida en un sistema distribuido, ya que solo le bastaría con conocer lo más relevante.
Ejemplo: El caso más común es el clúster de hadoop, lo podemos ver como un sistema distribuido, entonces, ¿Qué debería saber el zookeeper acerca de hadoop?, debería tener la información de que nodo es el namenode, la información acerca de los namenode que se encuentran en standby, Apache recomienda tener un máximo de 5 namenodes en un clúster y como mínimo para la alta disponibilidad un número de 2. Así que la información es mínima que en realidad guardamos en un clúster llamado como ensamblado cuando nos referimos a Zookeeper.

Cómo mencioné anteriormente un conjunto de servidores (nodos) se le da el nombre cuando usamos Apache Zookeeper de ensamblado, usualmente este conjunto de servidores deben ser del orden k = 2n+1 con n=1,2,..... (usualmente se utiliza un n con valor máximo como 3).
Pero uno se preguntará, por que debe ser un número impar el número de servidores en un ensamblado.
La respuesta viene a continuación con la siguiente demostración.
Empezaremos por definir la función piso.
Una vez definida la función piso, definiremos el número de nodos inaccesibles que puede tolerar un clúster con las características de zookeeper con la siguiente formula.
Con las dos definiciones anteriores estamos listos para probar por que un ensamblado de zookeeper necesita un número impar de servidores.


Como podemos ver el tener un clúster de la forma 2m no nos brinda ninguna ventaja mayor sobre un clúster de la forma 2m-1, ya que ambos casos tienen el mismo número de tolerancia a fallos.
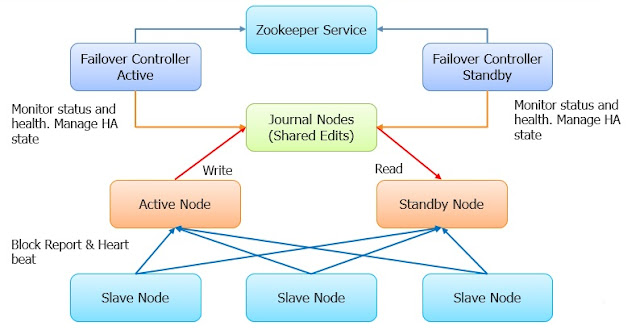
Ensamblado
El ensamblado cuenta al igual que todo clúster con un elemento principal, aquí en Apache Zookeeper recibe el nombre de leader, y es el que recibe las demás conexiones de los servidores restantes de el ensamblado.
Como podemos ver, hay m clientes conectados al ensamblado, estos m son servicios distribuidos como se ha mencionado anteriormente, aquí es donde empieza a entrar la magia de este componente, ya que si como cliente podemos ver a Hadoop, HBase, Spark, Kafka, Hive, etc o nuestros mismos servidos distribuidos es donde empezamos a ver el potencial de esta herramienta.
Al ser un sistema de coordinación de servicios distribuidos Zookeeper etiqueta todas las actualizaciones en su información con un número, que refleja el orden de todas las transacciones en el ensamblado y gracias a esto podemos obtener una abstracción de alto nivel de la información, como los clásicos synchronization primitives.
Apache asegura por medio de pruebas física en miles de máquinas que corrían zookeeper que es muy óptimo para operaciones de lectura que su contra parte la escritura en una relación 10:1, y esta bien, ya que la la mayoría de las aplicaciones de zookeeper son operaciones de lectura y no tantas de escritura, salvo cuando hay actualizaciones sobre la información de uno de sus clientes.
Quorum
Una de las características principales de zookeeper es que para realizar una operación el realiza internamente como un consejo, donde todos se lleva a cabo una votación para decidir si se lleva a cabo la operación o no, pero uno se preguntará, que número como mínimo se necesita para que zookeeper decida que puede realizarse la operación, a este concepto se le llama quorum y se puede definir como el número mínimo de Servidores que deben estar de acuerdo sobre una acción antes de considerarse como finalizada la operación y uno se preguntará, pero cual es ese número si tengo k servidores donde k es un número impar mayor a 3, la respuesta es fácil y la definiré a continuación.
Como anteriormente definimos un ensamblado debe ser de la forma anterior de acuerdo al teorema CAP, entonces tenemos un ensamblado de 2n+1 servidores, entonces dijimos que el quorum es el número de votos necesarios mínimos para finalizar una operación, entonces esto nos hace pensar que debería ser el número de servidores en el ensamblado más uno entre 2.
Entonces el quorum esta formado en cualquier ensamblado por un número de n+1, para sentenciar una operación como finalizada.
Data Model y Herarchical Namespace
El texto anterior son descripciones de algunas de las características que provee Zookeeper por si mismo, pero solo hemos mencionado que su información esta siempre en memoria y que es mínima, así que es tiempo de que hablemos de su Data Model y su Herarchical Namespace.
Estos dos componentes son algo más que tiene que ver con el modelo de información de Zookeeper 
Cómo podemos ver en la imagen anterior esta es la representación gráfica del namespace de Zookeeper al igual que HDFS Web Browser ha optado por tener una estructura similar a la de un File System Local. Este namespace cuenta con algunos componentes importantes como:
- name: El nombre no es más que en términos burdos la ruta, aunque para este propósito lo dejaremos como Apache da su definición, como "Una secuencia de elementos del tipo path separados por /".
- nodes: Un nodo es un elemento contenido en todos los paths.
- znodes: Un znodo es un elemento contenido en algunos paths que contienen información, si queremos hacer una comparación, sería como un datanode en hadoop.
Como vemos la imagen anterior es una representación gráfica de un ente como lo es un árbol en matemáticas.
Cada nodo puede componerse de dos elementos un nodo (hijo) ó un znode.
Cómo mencionamos anteriormente Zookeeper fue diseñado para guardar información acerca de la coordinación de un servicio distribuido en lo que podemos encontrar información como: información del estatus del servicio, configuración, localización de la información, etc) y aunque parezca que es mucha información lo que guarda zookeeper en realidad, es común que guarde información de la magnitud de byte o kilobyte.
Ahora hablemos de estos elementos que son los znodes el tiene una parte importante en todo lo de la coordinación, ya que contiene la información descrita en el párrafo anterior, un elemento importante de los znodes es que contiene una estructura llamada stat que se compone de version number (para la actualización de la información), ACL changes y timestamps. Los últimos dos elementos nos permiten validar sobre la cache y coordinar las actualizaciones en el ensamblado.
Como mencionamos anteriormente la versión de un znode es muy importante ya que nos permite hacer las actualizaciones de forma rápida, rápida y correcta, cada vez que un cliente recupera datos de los znodes, recibe las versión de estos.
Para finalizar de hablar de los znodes, debemos hablar que existen 3 tipos de estos los cuales son:
- Persistence znode: Persistence znode es aquel que sigue vivo incluso después que el cliente se desconecta del zookeeper, por default todos los znodes son de este tipo, hasta que se especifique lo contrario.
- Ephemeral znode: Ephemeral znode están activos mientras el cliente esta vivo, cuando el timeout llega a su limite entre el cliente y el server de el ensamblado todos los znode de este tipo son eliminados del ensamblado, por esta razón no es recomendable que este tipo de znodes tengan hijos más allá de ellos mismos. Si un znode de estos es eliminado el siguiente nodo más adecuado tomará su lugar, este tipo de objetos toman un rol muy importante en la elección de orquestadores en un servicio distribuido.
- Sequential znode: Sequential znodes pueden ser de de alguno de los dos tipos anteriores de znodes, lo que caracteriza a este elemento es que cuando se crea un znode de este tipo, zookeeper crea su path con una secuencia de 10 dígitos sobre el nombre original del znode, esto quiere decir que si creamos un znode llamado /test y es sequential znode, en la estructura del data model se escribirá como /test0000000001, cuando se cree un znode siguiente ahora será /test0000000002, etc. Zookeeper nos provee un elemento importante para manejar el caso en que dos znodes se creen al mismo tiempo y eso es la consistencia en la secuencia, lo cual permite que nunca se repita el nombre de dos znodes de este tipo. Estos znodes son de mucha utilidad para la sincronización y
Con los znodes viene otro componente importante que se denominan watches.
Watches
Este tipo de elemento trabaja como un mecanismo para obtener notificaciones acerca de los cambios que se realicen en el ensamblado, pero también los podemos utilizar cuando un cliente lee un znode en particular. Los whatches mandan notificaciones a los clientes que estén registrados en cualquiera de los znodes que registren un cambio.
Podemos definir un cambio en un znode como una modificación a la información del znode o la de alguno de sus hijos. Los watches son enviados solo una vez, por lo que si el cliente quiere lanzar más de una vez el watch deberá realizar una operación de lectura para ser posible, al igual que los ephemeral znodes, el ciclo de vida de los whatches es mientras la conexión del cliente permanece viva.
Sesiones
Las sesiones son un elemento importante de interacción entre los clientes y servidores para las peticiones, cuando un cliente negocia una sesión con un servidor, las peticiones que se transmitirán en esta sesión se realizan con una linea de espera
Pero este no es el único uso de una sesión, también sirve para saber si el servidor o el cliente siguen vivos ya que el cliente manda heartbeats en un lapso de tiempo en particular para mantener la sesión activa, si el cliente deja de enviar estos heartbeats el server del zookeeper decide que se murió el cliente y corta toda la comunicación con este, el timeout usualmente se maneja en milisegundos y todos los ephemeral znodes creados durante la sesión serán eliminados cuando esta termine.
Finalmente podemos afirmar algunas cosas de este servicio distribuido que sirve para la coordinación de sistemas distribuidos, ya que fue pensado más que como un servicio complejo fue pensado como la base de todo sistema distribuido para que sea más complejo y fácil de administrar, entre las garantías que Apache asegura que podemos esperar de Zookeeper encontramos.
- Atomicity: Las actualizaciones solo son exitosas o no. No puede haber resultados parciales
- Sequential Consistency: Actualizaciones mandadas desde un cliente se aplicarán en el orden en que son mandadas.
- Reliability: Una vez que el cliente realice una actualización sobre alguna información esta se mantendrá hasta que el cliente vuelva a actualizarla.
- Single System Image: El cliente siempre tendrá acceso a la misma información independientemente del servidor al que se conecte en el ensamblado.
- Timeliness: El la información a la que puede acceder el cliente se garantiza tener la información más actualizada correspondiente a una cota limite de tiempo.
Pero como es que usamos todas las características y bondades que nos brinda zookeeper de acuerdo a nuestras necesidades.
Apache nos provee un API muy sencilla de usar para el manejo de los componentes de zookeeper las cuales listaré a continuación:
- create
- delete
- exists
- get data
- set data
- get children
- sync



Comentarios
Publicar un comentario